Für das Fach Software-Engineering sollte eine einfache Projektverwaltung erstellt werden, ich habe daraus eine Multi-User-fähige Java-Anwendung gemacht welche über RMI funktioniert. Das bedeutet ich habe einen eigenen Anwendungsserver und – Client implementiert.
Der Anwendungsserver
Mein Anwendungsserver benutzt die Remote Method Invocation (RMI) von Java um entfernte Methodenaufrufe über ein Netzwerk zu ermöglichen. Als Datenbank wird wieder HSQLDB benutzt, als Datenbankzugriffsschicht die Java Persistence API (JPA)-Implementierung EclipseLink, als Logging-Framework wird Apaches Log4j und für Performance-Messungen JAMon verwendet.
Initialisierung des Servers
Den Server habe ich immer in eine ausführbare JAR-Datei kompiliert und dann mittels des Kommandozeilenbefehls (in der Eingabeaufforderung) java –jar RMIServer.jar ausgeführt. Bei der Initialisierung des Servers geschieht intern in dieser Reihenfolge:
1. Initialisierung zweier Logger-Instanzen (log4j), consoleLogger und fileLogger. Generell ist es so dass Meldungen die über den consoleLogger gemeldet werden auf der Kommandozeile wie auch in der Log-Datei geloggt werden und fileLogger-Meldungen nur in die Log-Datei.
Der Sinn liegt darin dass der Server einen Eingabeprompt anbietet, sobald dieser erscheint sollen nur noch Fehlermeldungen auf der Konsole und die Infomeldungen direkt in die Log-Datei geschrieben werden – ansonsten würde der Eingabeprompt untergehen.
2. Setzen einer eigenen SocketFactory – dazu habe ich eine eigene Klasse CustomRMISocketFactory erstellt, die mittels der Befehle
try {
customRMISocketFactory = new CustomRMISocketFactory();
RMISocketFactory.setSocketFactory(customRMISocketFactory);
} catch (IOException e) {
RmiServer.consolelogger
.error(Messages.getString("RmiServer.16") + e.getMessage()); //$NON-NLS-1$
}
als aktiv geschaltet wird. Der Server muss nämlich auch den Client direkt verbinden können und das Problem dabei war dass ein Client mehrere Netzwerkschnittstellen haben kann von denen aber nicht alle von außen erreichbar sein müssen.
Denn RMI benutzt ansonsten irgendeine IP-Adresse des Clients und scheitert unter Umständen bei der Verbindungsherstellung. Das Problem trat bei mir besonders zutage da ich intensiv mit virtuellen Maschinen teste, diese mit virtuellen Netzwerkadaptern arbeiten und abgeschottet sein sollen.
Um dieses Problem zu umgehen wird während des Anmeldens des Clients beim Server dessen aktive IP-Adresse mittels des Befehls RemoteServer.getClientHost() in der Klasse ObserverUpdater zwischengespeichert.
Die Server-Anwendung kennt zwei Methoden des Datenauslieferns: 1. direktes Daten-Zurückliefern, wie es üblich ist und 2. das Abonnement/Observer-Prinzip. Bei der Observer-Methode werden die Daten an alle Beobachter ausgeliefert die in die Observer-Liste beim Anmelden eingetragen wurden.
Der Sinn bei der Observer-Methode besteht darin den Datenbankserver zu entlasten und alle Clients gleichzeitig auf dem aktuellen Datenstand zu halten. Der allgemeine Netzwerktraffic wird dann unter Umständen erhöht, jedoch stellt eher der Datenbankserver einen Engpass im Netzwerk dar. Der Netzwerktraffic allein verursacht kaum Rechenlast; nicht zuletzt deswegen werden viele NAS-Server mit Atom-Prozessoren ausgeliefert und können ein Gigabit-Netzwerk geschwindigkeitsmäßig beim Dateizugriff durchaus auslasten – sofern sie nicht parallel anderweitig belastet werden.
Wenn Daten nun über die Observer-Methode ausgeliefert werden wird zunächst der activeObserver gesetzt und die CustomRMISocketFactory benutzt dann nicht mehr die ihr direkt übergebene IP-Adresse sondern die activeObserver-IP-Addresse aus der ObserverUpdater-Klasse. Auf diese Weise wird für die Client-seitige Verbindung immer die korrekte IP-Adresse genommen.
Es ist übrigens bei RMI zwingend notwendig sämtliche Client-Firewalls komplett zu deaktivieren. Serverseitig muss nur Port 1099 freigeschaltet werden, aber bei der Client-seitigen Kommunikation werden zufällige Ports verwendet, wie auch der Beitrag bei stackoverflow offenbart. An der Stelle macht sich bemerkbar dass RMI für Firmen-Netzwerke konzipiert wurde, denn dort werden generell alle Client-Firewalls deaktiviert und der gesamte Traffic über einen Server geroutet.
3. Setzen eines RMI-SecurityManagers. Sobald eine Java-Anwendung in Packages aufgeteilt wird muss ein RMI-SecurityManager benutzt werden, weil sonst die Kommunikation über RMI nicht mehr funktioniert. Ein solcher muss sowohl im Client als auch im Server gesetzt werden, dazu erforderlich sind passende policy-Dateien die den Rechtezugriff regeln. Diese müssen bei mir im jeweils gleichen Verzeichnis wie der Client/Server liegen.
Zu beachten ist dabei übrigens auch dass das Server-seitige Package, welches die Implementierung des Server-Interfaces enthält, den gleichen Namen haben muss wie das Client-seitige Package in welchem das Server-Interface enthalten ist.
Wenn man diese Punkte nicht beachtet gibt es Fehlermeldungen bei der RMI-Kommunikation.
4. Übergebene Kommandozeilenargumente auswerten. Die ausgewerteten Parameter sind, in dieser Reihenfolge: 1. der zu verwendende Port – standardmäßig ist dies bei RMI 1099, 2. mittels des Befehls “createRegistry=true/false” wird entweder die RMI-Registrierung programmseitig erstellt oder eine bereits vorhandene geholt.
Der zweite Parameter ist sinnvoll wenn weitere RMI-Dienste auf dem Server angeboten werden sollen, weil die RMI-Registry nur einmal erstellt werden kann. Wird createRegistry=false beim Starten gesetzt muss sie zuvor separat durch den Befehl
start rmiregistry -J-classpath -J"RMIServer.jar”
gestartet worden sein.
5. Gegebenenfalls starten einer eigenen RMI-Registrierung, ansonsten holen der RMI-Registrierung.
6. Instanziieren der ServerInterface-Implementierung und binden dessen an die Registrierung unter einem bestimmten Namen, der üblicherweise dem Anwendungsnamen entspricht.
7. Herstellen der Verbindung zur HSQLDB-Datenbank - generell werden diese Zugriffe in der ModelController-Klasse geregelt. Da die Datenbank lokal auf dem Server liegt muss sich nicht um datenbankseitige Verbindungstrennungen und Reconnects gekümmert werden. Um netzwerkseitige Verbindungstrennungen kümmert sich RMI übrigens automatisch.
8. Hinzufügen eines Shutdownhooks. Normalerweise können alle Konsolenprogramme mittels des Befehls Strg-C unterbrochen werden, aber auf diese Weise wird das abgefangen und die Datenbank immer sauber heruntergefahren.
Im HSQLDB-Connectionstring steht zwar shutdown=true so dass sie automatisch beim Verlust der einzigen zulässigen Verbindung (ist als Embedded-Datenbank konfiguriert) herunterfährt, aber trotzdem müssen die Ressouren freigegeben werden – der EntityManager und die EntityManagerFactory von EclipseLink.
Wenn die Datenbank sauber heruntergefahren wurde sieht man das daran dass die Lock-Datei gelöscht wurde.
9. Starten eines eigenen Threads, der den Eingabeprompt anbietet und auf Eingaben reagiert. Dazu muss ein neuer Thread benutzt werden weil sonst die Hauptaufgabe des Servers – das Reagieren auf Befehlen – blockiert werden würde.
Im Eingabeprompt kann durch die Eingabe von q das Programm beendet werden, wird etwas anderes eingegeben wird der Prompt wiederholt ausgegeben.
Anbieten von Funktionen über RMI
Bei RMI können sowohl Client als auch Server sich gegenseitig Funktionen anbieten, die dann remote aufgerufen werden. Dazu wird dem Server das Client-Interface und dem Client das Server-Interface zur Verfügung gestellt, außerdem muss natürlich der Client das Client-Interface und der Server das Server-Interface tatsächlich implementieren.
Übrigens sollten sämtliche Server/Client-Remote-Objekte als statisch deklariert werden, damit sie niemals vom Garbage Collector abgeräumt werden.
Nachfolgend die angebotenen Funktionen des Servers; der Inhalt des Server-Interfaces:
/**
* Schnittstelle der Funktionen des Servers
*
* Version 1.0.07022013
*
* @author Thomas Kramer, eMail: th-rzv@gmx.de
*
*/
public interface ServerInterface extends Remote {
String SERVICE_NAME = "Projektverwaltung";
public void addObserver(ClientInterface remoteObserver)
throws RemoteException;
public void removeObserver(ClientInterface remoteObserver)
throws RemoteException;
public void selectData(Class tableName) throws RemoteException;
public List<Object> getData(Class tableName) throws RemoteException;
public List<Object> getDataWithClause(Class tableName, String column,
String clause) throws RemoteException;
public List<Object> getDataWithClause(Class tableName, String column,
Integer clause) throws RemoteException;
public boolean insertData(Object type) throws RemoteException;
public boolean changeData(Object tableName) throws RemoteException;
public boolean deleteData(Object tableName) throws RemoteException;
}
Nachfolgend die angebotenen Funktionen des Clients; der Inhalt des Client-Interfaces:
/**
* Schnittstelle der Funktionen des Clients
*
* Version 1.0.0007
*
* @author Thomas Kramer, eMail: th-rzv@gmx.de
*
*/
public interface ClientInterface extends Remote {
void update(Class t, List<Object> o) throws RemoteException;
void serverTerminated() throws RemoteException;
}
Um sicherzustellen dass Client und Server immer auf dem jeweils aktuellen Schnittstellenstand sind sollte man natürlich Versionsnummern als Kommentare einführen.
Entity-Klassen von EclipseLink
Die Entity-Klassen aller Datenbanktabellen wurden ursprünglich aus den Tabellen über einen Eclipse-Menüpunkt automatisch generiert und sind ein Abbild von diesen, da EclipseLink ein objektrelationaler Mapper ist. Diese Entity-Klassen müssen auch dem Client bekannt gemacht werden, dementsprechend bei Änderungen ins Client-Projekt kopiert werden.
Die Vorteile liegen darin dass bei einer vom Server zurückgelieferten Entity-Instanz die Bean-Getter im Client ausgeführt werden können obwohl die Datenbankverbindung selbst nur im Server existiert. Das bedeutet praktisch dass EclipseLink beim Auslesen eines Tabellen-Eintrages aus der Datenbank auch automatisch seine referenzierten Einträge anderer Tabellen mitausliest, denn ansonsten würde das so nicht funktionieren.
Ein weiterer Vorteil liegt darin dass die Unterscheidung dessen, was gerade an Daten benötigt oder gespeichert werden soll, im Client gemacht werden kann und die Fallunterscheidungen im Server entfallen. Ein Beispiel beim Erstellen eines neuen Projektes:
Die Datenbanktabelle heißt Projekt und die Entity-Klasse ebenso. Im Client wird das Projekt-Objekt instanziiert, über die Setter seine Daten gesetzt und das Objekt der insertData(Object type)-Methode des Servers übergeben, welche lediglich anhand des generischen Typs Objekt unterscheidet. Alle Entity-Klassen von EclipseLink (natürlich nicht nur diese….) leiten nämlich von Objekt ab.
Das bedeutet wiederum dass die insertData, changeData und deleteData-Methoden im Server nie erweitert werden müssen, egal wieviele Datenbanktabellen und Entity-Klassen noch hinzugefügt werden.
Generell kann man dazu auch sagen dass in Richtung Server generalisiert und in Richtung Client spezialisiert wird. Das Ziel ist es sowenig Fallunterscheidungen wie möglich einzubauen und somit die notwendige händische Nacharbeit zu begrenzen.
Leider gibt es Grenzen beim Abbild der Datenbanktabellen auf Klassen, z. B. werden die Begrenzungen, wie lang ein Textfeld in einer Datenbank sein kann, nicht automatisch in die Entity-Klassen übernommen. Dazu ist es notwendig Column-Annotationen händisch in die Entity-Klassen zu setzen, z. B.
@Column(length = 30)
private String email;
Das bedeutet dass der String eMail eine Annotation hat die ihn sinngemäß auf eine maximale Länge von 30 Zeichen setzt. Man sieht dass der entsprechende Annotationstyp per default schon existiert, nur werden sie beim Erstellen der Entity-Klassen nicht automatisch übernommen.
Die praktische Vorgehensweise bestand darin die Entity-Klassen vom Server in den Client zu kopieren und nur dort die Column-Annotationen händisch zu setzen – tat man dies bereits bei den Entity-Klassen im Server gab es beim Starten des Servers Fehlermeldungen. Nur bei den Client-Entity-Klassen akzeptiert er diese Annotationen. An der Stelle ist leider händisches Nacharbeiten notwendig.
Praktisch habe ich dann diese Annotationen im Client ausgelesen und die Länge der Textfelder entsprechend begrenzt. Das Ziel dabei war keine Konstanten einfach irgendwo in den Quellcode zu setzen sondern sie an zentraler Stelle zu sammeln.
Funktionen des Servers
Anhand des Server-Interfaces oben kann man sehen welche Funktionen der Server dem Client zur Verfügung stellt. Wo es möglich war wurden übrigens keine Objekt-Instanzen sondern nur der Class-Typ übergeben.
Die Funktionen sind:
- void addObserver(ClientInterface remoteObserver): Fügt den aktuellen Client der Liste von Observern hinzu, geschieht beim Anmelden des Clients beim Server.
- void removeObserver(ClientInterface remoteObserver): Entfernt den aktuellen Client wieder aus der Liste von Observern, geschieht beim Beenden des Clients.
- void selectData(Class tableName): Liest Daten aus der Datenbank anhand des Entity-Klassentyps aus und liefert sie an alle Beobachter/Observer aus.
- List<Object> getData(Class tableName): Liest Daten aus der Datenbank anhand des Entity-Klassentyps aus und liefert sie direkt nur an diesen Client zurück.
- List<Object>
: Liest Daten aus der Datenbank anhand des Entity-Klassentyps aus, wobei auch eine Bedingung übergeben wird. Hierbei ist zu beachten dass der Typ der Bedingung einem String entspricht – das muss entsprechend der Entity beachtet werden. Man könnte beispielsweise nicht auf ein ID-Feld mit dieser Funktion abfragen.
- List<Object>
: Liest Daten aus der Datenbank anhand des Entity-Klassentyps aus, wobei auch eine Bedingung übergeben wird. Hierbei ist zu beachten dass der Typ der Bedingung einem Integer entspricht – das muss entsprechend der Entity beachtet werden. Man könnte hiermit auf ein ID-Feld mit dieser Funktion abfragen.
- boolean insertData(Object type): Schreibt einen neuen Datensatz in die Datenbank und liefert den Erfolg dieser Aktion zurück. Fehlermeldungen werden nicht direkt zurückgeliefert sondern in die Log-Datei des Servers geschrieben.
- boolean changeData(Object tableName): Ändert einen vorhandenen Datensatz in der Datenbank und liefert den Erfolg dieser Aktion zurück. Fehlermeldungen werden nicht direkt zurückgeliefert sondern in die Log-Datei des Servers geschrieben.
- boolean deleteData(Object tableName): Löscht einen vorhandenen Datensatz in die Datenbank und liefert den Erfolg dieser Aktion zurück. Fehlermeldungen werden nicht direkt zurückgeliefert sondern in die Log-Datei des Servers geschrieben.
Der Spalten-Typ bei den getDataWithClause-Funktionen wird als String übergeben, dementsprechend ist natürlich die Typsicherheit an der Stelle nicht gewährleistet. Leider habe ich keine Möglichkeit gefunden den Column-Typ im Client auszulesen und dem Server direkt zu übergeben. Die Implementierung dieser Funktionen erfolgt im ModelController, dort wird dieser Spaltenname aber eh als String an EclipseLink übergeben, da JPQL sich an SQL orientiert. Damit die Fehlerfreiheit an der Stelle langfristig gewährleistet bleibt sollte man sich angewöhnen niemals die Datenbankspalten nachträglich umzubenennen, aber das macht sowieso niemand.
Wenn der Server beendet wird werden übrigens auch alle Clients automatisch mit einer Fehlermeldung beendet, da diese ohne den Server nicht weiterlaufen können. Hierbei war zu beachten dass der Client beim Empfangen des Terminate-Befehls vom Server für das Beenden einen neuen Thread startet, da sonst der Server auf die Beendigung aller Clients wartet bevor er sich selbst beendet.
Umsetzung des Observer-Auslieferungsprinzips im Server
Das Observer-Prinzip habe ich schon grob umschrieben. Das Hinzufügen von Observern geschieht beim Anmelden des Clients beim Server, dazu werden die Daten in zwei ArrayListen gespeichert:
private static final ArrayList<ClientInterface> remoteObserverList;
private static final ArrayList<String> remoteObserverListHostNames;
Die remoteObserverList wird mit dem neuen Client gefüllt und die remoteObserverListHostNames enthält die IP-Adresse des Clients, über den die Verbindung beim Anmelden bereits einmal funktioniert hat. Der Zusammenhang wird hergestellt über den gleichen Index dieser beiden ArrayListen. Diese IP-Adresse wird von der CustomRMIFactory dann benutzt, dazu wird der gerade aktive Observer zuvor mit activeObserver gesetzt.
Für die weitere Vorgehensweise siehe die ObserverUpdater-Klasse.
Eine weitere wichtige Funktion des Servers ist folgendes: Die Projekt-Tabelle referenziert beispielsweise die Tabelle Ansprechpartner. Wird nun ein Ansprechpartner geändert oder gelöscht werden automatisch alle Datensätze aus der Projekt-Tabelle erneut ausgelesen und an alle Clients verteilt.
Der Sinn besteht darin dass alle Clients stets auf dem aktuellen Datenstand sein und keiner veraltete Datensätze anzeigen soll. Dazu werden beim Starten des Servers im ModelController zunächst alle von EclipseLink gemanagten Entity-Klassen ausgelesen und in einer ArrayList zwischengespeichert:
/**
* Einlesen der Entity-Klassen
*/
tableList = new ArrayList<ManagedType<?>>();
for (ManagedType<?> table : em.getMetamodel().getManagedTypes()) {
tableList.add(table);
}
Wurde nun ein Datensatz bzw. eine Entity aktualisiert wird nachfolgender Code aufgerufen der alle abhängigen Entities neu ausliest:
/**
* Aktualisieren der Entities
*
* @param entity
* Entity
*/ private static void refreshEntities(Object entity) {
/**
* Cache aktualisieren
* http://wiki.eclipse.org/EclipseLink/Examples/JPA/Caching
* #How_to_refresh_the_cache
*/ emf.getCache().evictAll();
/**
* Tabellen sollen nicht mehrfach refresht werden
*/
HashSet<Class> tablesHashSet = new HashSet<Class>();
Class tempClass;
/**
* Views aktualisieren
*/
selectData(entity.getClass());
/**
* von der Tabelle referenzierte Tabellen refreshen
*/
for (ManagedType<?> table : tableList) {
for (Attribute<?, ?> test : table.getAttributes()) {
if (test.getJavaType().isAssignableFrom(entity.getClass())) {
tempClass = table.getJavaType();
if (!tablesHashSet.contains(tempClass)) {
selectData(tempClass);
tablesHashSet.add(tempClass);
}
}
}
}
}
Die neuen Daten werden wiederum über das Observer-Pattern an alle als Observer/Beobachter registrierten Clients ausgeliefert.
Wichtig dabei war die Daten aus der gleichen Tabelle nicht hintereinander mehrmals auszulesen. Der Projekt-Entity beispielsweise können drei Studenten gleichzeitig zugeordnet werden, trotzdem sollen nur einmal alle Datensätze aus Projekt neu ausgelesen werden wenn ein Student geändert oder gelöscht wurde. Daher wurde ein lokales HashSet an der Stelle benutzt um dies sicherzustellen.
Die abhängigen Daten werden dann in selectData neu ausgelesen welche wiederum getData aufruft. Diese sieht folgendermaßen aus:
public static List<Object> getData(Class tableName) {
/**
* Instanziieren und Starten des Performance-Monitors
*/
Controller.performanceMonitor = MonitorFactory.start(Messages
.getString("ModelController.4") //$NON-NLS-1$
+ tableName.getName());
/**
* Auslesen der Daten
*/
List<Object> results = null;
try {
Query query = em.createQuery("SELECT C FROM " + tableName.getName() //$NON-NLS-1$
+ " C"); //$NON-NLS-1$
results = query.getResultList();
} catch (Exception e) {
System.out.println(""); //$NON-NLS-1$
RmiServer.consolelogger.error(Messages
.getString("ModelController.0") + e.getMessage()); //$NON-NLS-1$
}
/**
* Stoppen des Performance-Monitors
*/
Controller.performanceMonitor.stop();
/**
* Performance-Messung loggen
*/
RmiServer.fileLogger.info(Controller.performanceMonitor);
return results;
}
Man sieht dass eine Performance-Messung mittels JAMon stattfindet und geloggt wird, diese lasse ich nur beim Auslesen ALLER Datensätze aus einer Tabelle geschehen – beim Anfordern eines einzelnen Datensatzes dauert sonst das Loggen länger als das Auslesen, das wäre nicht sinnvoll. Es ist übrigens aus Performance-Gründen sehr wichtig Indizes in die Datenbank auf alle Foreign-Key-Spalten zu setzen.
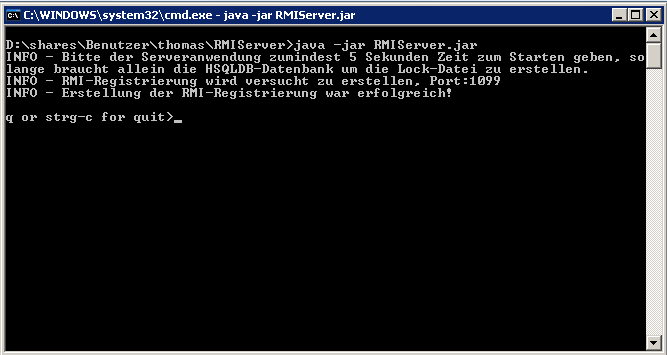
Nachfolgend ein Bild der Konsolenausgaben des Servers:
Nachfolgend ein Bild der Logging-Ausgaben des Servers:
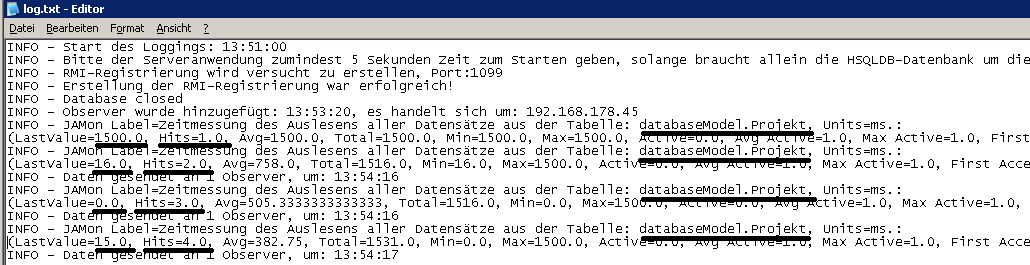
Die relevanten Stellen habe ich unterstrichen. Man sieht dass viermal hintereinander alle Daten aus der Projekt-Tabelle ausgelesen wurden. Bei Hits sieht man den jeweiligen Versuch, LastValue zeigt an wieviele Millisekunden der aktuelle Versuch benötigt hat. Es ist logisch dass der erste Versuch am längsten Zeit benötigt. JAMon ermittelt auch automatisch den durchschnittlichen Zeitaufwand über alle Versuche.
Bei HSQLDB sind Performance-Messungen eher weniger erforderlich weil es doch eher als RAM-Datenbank ausgelegt ist, sprich sämtliche Daten im Arbeitsspeicher vorgehalten werden. Das macht es sehr schnell - außerdem ist HSQLDB sehr gut fürs Rapid Prototyping geeignet weil nicht einmal ein SQL-Tool benötigt wird.
Für den praktischen Einsatz würde ich dann aber doch eher Oracle oder SQLServer präferieren die es auch in kostenlosen Versionen gibt – früher hätte ich eindeutig Firebird bevorzugt aber ich berücksichtige mittlerweile stark die berufliche Relevanz.
Mein Anwendungsserver implementiert jedenfalls alle grundlegenden Datenbank-Operationen – Einfügen, Ändern und Löschen von Datensätzen. Allerdings immer nur einen Datensatz auf einmal – beim Einfügen von vielen Datensätzen auf einmal wäre als Übergabeparameter eine Liste von Objekten statt eines einzelnen Objektes sinnvoll, damit die Transaktion nur einmal ausgeführt wird. Aber das wäre nur eine geringfügige Erweiterung und würde kein Problem darstellen sie nachträglich einzuführen – wenn dann aber nur als überladene Methode, bei einem einzelnen Objekt würde das sonst eine Verlangsamung darstellen. Für diese Anwendung macht eine solche Erweiterung jedenfalls keinen Sinn.
Ansonsten war es bei der HSQLDB-Datenbank des Servers noch wichtig den Transaktionstyp auf RESOURCE_LOCAL zu stellen, entsprechend der Konfiguration der Datenbank als eingebettetes System.
Update 14.02.2013: Bei einer Datensatzänderung oder –löschung werden bislang die von dieser Tabelle abhängigen anderen Tabellen ermittelt und aus denen jeweils alle Datensätze erneut ausgelesen und verteilt. Ich habe mir nochmal überlegt inwieweit das sinnvoll ist.
Eigentlich denke ich dass wenn auf das Foreign-Key-Feld abhängiger Tabellen kein Datenbank-Index gesetzt wurde eine zusätzliche WHERE-Bedingung die Abfrage sogar verlangsamen könnte. Schließlich werden bei mir zwar alle Datensätze aus der Tabelle zu dem Zweck ausgelesen, aber genauso wie sie in der Datenbank gespeichert wurden – ohne ORDER BY-Sortierung.
Eine zusätzliche WHERE-Bedingung könnte daher u. U. sogar langsamer sein als einfach alle Datensätze aus der abhängigen Tabelle auszulesen, zumindest bei der Reihenfolge wie sie gespeichert wurden. Außerdem werden die Datensätze ja nur einmal ausgelesen und dann nur noch an alle Clients verteilt.
Zudem, wenn ich nicht mehr alle Datensätze abhängiger Tabellen bei Änderungen auslesen lasse müsste ich das kaskadierende Löschen von Detaildatensätzen der Datenbank im Client anders abfangen – über eine separate Datenbankabfrage.
Update 18.02.2013: Eine zusätzliche WHERE-Bedingung beim Aktualisieren abhängiger Daten würde auf jeden Fall bedeuten dass den Clients zusätzliche Rechenlast aufgebürdet wird. Denn wenn diese nunmal alle Datensätze auf einmal darstellen und es werden nur noch die geänderten Datensätze bei Änderungen automatisch transferiert, dann müssen die Clients die Neue mit der alten Liste von Objekten erst zusammenführen.
Das ist dann also auch eine Entscheidung zwischen Netzwerk-Traffic oder Client-Rechenlast.
Die gegenwärtige Lösung funktioniert jedenfalls einwandfrei und ist für kleinere bis mittlere Projekte ausreichend.
Update 24.02.2013: In diesem Weblog wird dagegen davon abgeraten als Transaktionstyp RESOURCE_LOCAL bei Anwendungsservern zu verwenden; damit muss ich mich später noch befassen, funktionieren tut es jedenfalls einwandfrei. Interessant wären später noch Last-Tests, aber dazu müsste ich idealerweise auch noch die Datenbank wechseln.
Der Anwendungsclient
Der Anwendungsclient benötigt ebenfalls die EclipseLink-Bibliotheken, damit er mit den Entity-Klassen umgehen kann.
Wie weiter oben bereits gesagt muss die Client-Firewall komplett deaktiviert werden damit die Kommunikation über RMI funktioniert, da client-seitig zufällige Ports verwendet werden. Die Port-Angabe über die Kommandozeilenparameter spezifiziert den Port des Servers, nicht des Clients.
Die Initalisierung des Clients erfolgt folgendermaßen:
1. Übergebene Kommandozeilenargumente auswerten. Die ausgewerteten Parameter sind, in dieser Reihenfolge: 1. der zu verwendende Port – standardmäßig ist dies bei RMI 1099, 2. die IP-Adresse bzw. der Hostname des Servers.
2. Setzen des RMI-SecurityManagers, die client.policy-Datei wird dazu im gleichen Verzeichnis benötigt.
3. Holen der RMI-Registrierung vom Server, unter Verwendung der übergebenen Kommandozeilenparameter.
4. Suchen des Serverdienstes in der Registrierung über den Anwendungsnamen, binden dessen an eine Variable.
5. Instanziieren des Login-Formulares, mit dem sich nach Auswahl der Benutzerrolle eingeloggt oder die Anwendung alternativ vorzeitig beendet werden kann.
Der Client implementiert das Client-Interface – wenn er Daten vom Server indirekt als Beobachter/Observer empfängt delegiert er diese Daten anwendungsintern an den Controller weiter, der sie über die Java-interne Observer-Implementierung an alle Formulare und Dialoge weiterleitet welche die update-Methode implementieren.
Da es in Java nicht so einfach möglich ist aus einer generischen Klasse den inneren Typ auszulesen werden diese Daten zuvor in ein Objekt der ResultContent-Klasse gekapselt. Diese enthält zwei Methoden, eine um den Typ und eine zweite um den Inhalt der Daten auszulesen.
Formular- und Dialog-Handling
Der Client geht mit einer gewissen Strategie vor um den Nutzen des Observer-Patterns zu maximieren. Im Allgemeinen wird im Konstruktor eines Formulares ein Daten-Laden veranlasst um das Formular mit bestimmten Daten vorzubelegen – z. B. Comboboxen, die Inhalte aus der Datenbank anzeigen sollen.
Dazu muss man sich bewusst machen dass im Konstruktor eines Formulares das Observer-Pattern noch nicht benutzt werden kann, weil erst danach das Formular-Objekt als Observer dem Controller hinzugefügt wird. Es ist daher notwendig im Server auch eine Methode zu implementieren die die Daten direkt zurückliefert – diese wird im Konstruktor eines Formulares aufgerufen, deren Inhalte in einer Liste von Objekten zwischengespeichert und die Update-Methode direkt aufgerufen.
Nun kann man sich überlegen ob es wirklich notwendig ist ein Formular jedesmal neu zu instanziieren wenn man den entsprechenden Menüpunkt oder Button erneut anklickt. Es gibt verschiedene Möglichkeiten:
1. Alle Formulare werden beim Programmstart direkt instanziiert und erst bei Benutzer-Interaktion angezeigt
2. Das Formular wird bei der Benutzer-Interaktion immer neu instanziiert und angezeigt
3. Formulare werden immer nur bei der ersten Benutzer-Interaktion neu instanziiert, ansonsten geholt
Von der ersten Methode ist abzuraten weil das unnötigen Speicherverbrauch verursachen und den Programmstart verzögern würde. Die zweite Methode wird häufig benutzt aber ist eher schlecht – als Anwender erwarte ich zu Recht dass sich ein Fenster beim zweiten Mal schneller öffnet als beim ersten Mal, und das ist damit nicht gegeben.
Die dritte Methode ist am besten und wird auch in Oracles MVC-Artikel erläutert. Ich verwende dazu im Client-Controller zwei verschiedene ArrayListen:
/**
* interne Liste von Frames/Dialogs
*/ private static ArrayList<AbstractFrame> viewFrames =
new ArrayList<AbstractFrame>();
private static ArrayList<AbstractDialog> viewDialogs =
new ArrayList<AbstractDialog>();
/**
* Anzahl der Frames/Dialogs die in den Arraylisten gleichzeitig vorgehalten
* werden
*/
private static int framesLimit = 2;
private static int dialogsLimit = 2;
Diese ArrayListen speichern zentral alle Formular- und Dialog-Objekte. Dazu passend gibt es verschiedene Methoden im Controller:
/**
* einen bestimmten JFrame aus der Controller-Liste auslesen und zurückgeben
*
* @param jFrame
* @return
*/ public AbstractFrame getFrame(Class jFrame) {
AbstractFrame result =
null;
for (AbstractFrame view : viewFrames) {
if (view.getClass().equals(jFrame)) {
result = view;
break;
}
}
return result;
}
/**
* fügt einen bestimmten JFrame der internen Controller-Liste hinzu
*
* @param jDialog
*/
public void addFrame(AbstractFrame jFrame) {
viewFrames.add(jFrame);
if (viewFrames.size() > framesLimit) {
viewFrames.remove(0);
System.out
.println("Listenkapazität der JFrames im Controller überschritten, das erste Element wurde wieder entfernt!");
}
}
/**
* einen bestimmten JDialog aus der Controller-Liste auslesen und
* zurückgeben
*
* @param jFrame
* @return
*/
public AbstractDialog getDialog(Class jDialog) {
AbstractDialog result = null;
for (AbstractDialog view : viewDialogs) {
if (view.getClass().equals(jDialog)) {
result = view;
break;
}
}
return result;
}
/**
* fügt einen bestimmten JDialog der internen Controller-Liste hinzu
*
* @param jDialog
*/
public void addDialog(AbstractDialog jDialog) {
viewDialogs.add(jDialog);
if (viewDialogs.size() > dialogsLimit) {
viewDialogs.remove(0);
System.out
.println("Listenkapazität der JDialogs im Controller überschritten, das erste Element wurde wieder entfernt!");
}
}
Diese Controller-Methoden bieten Funktionen an um einen Dialog bzw. ein Formular aus den ArrayListen entweder zu finden und zurückzugeben oder direkt hinzuzufügen. Dazu begrenze ich die Anzahl der gleichzeitig vorgehaltenen Formular bzw. Dialog-Objekte über Konstanten auf zwei Einträge, damit sich der Speicherverbrauch in Grenzen hält.
Wird beim Hinzufügen diese Kapazität überschritten wird das erste Objekt wieder aus der Liste entfernt und eine Meldung auf der Konsole ausgegeben. Meine Anwendung ist klein und hat nur vier Dialoge, daher die Begrenzung auf zwei Objekte zum Testen.
Wenn man sich nun in die Anwendung einloggt wird nach dem Login-Formular das MainFrame-Formular angezeigt, dazu wird folgende Funktion ausgeführt:
/**
* Einloggen mit Benutzerrolle
*
* @param role
* Rolle, 0=Student, 1=Dozent
*/ private void login(UserRole role) throws RemoteException {
/**
* Anmelden als Beobachter/Observer beim Server RemoteExceptions werden
* nach "oben" weitergerreicht und im Controller abgehandelt
*/ Controller.rmiClient =
new ClientInterfaceImpl();
Controller.rmiServer.addObserver(Controller.rmiClient);
/**
* nachfolgend Client-Internes anmelden
*/
AbstractFrame viewMF = null;
/**
* View aus Frame-Liste des Controllers holen, soll nicht immer neu
* instanziiert werden
*/
viewMF = controller.getFrame(MainFrame.class);
/**
* noch nicht in View-Liste des Controllers, instanziieren und
* hinzufügen
*/
if (viewMF == null) {
viewMF = new MainFrame(controller, role);
/**
* als Beobachter hinzufügen
*/
controller.addObserver(viewMF);
/**
* der Dialog-Liste im Controller hinzufügen
*/
controller.addFrame(viewMF);
}
viewMF.setSize(800, 300);
// viewMF.pack();
// positionieren des Fensters: mittig
viewMF.setLocationRelativeTo(null);
viewMF.setVisible(true);
}
Auf diese Weise findet das erneute Öffnen eines Formulares oder Dialoges immer schneller als beim ersten Mal statt und der Nutzen des Observer-Patterns wird maximiert. Schließlich hat man vom Observer-Pattern nur wenig wenn das Daten-Laden im Konstruktor des Formulars stattfindet und das Formular jedesmal neu instanziiert wird – diese Vorgehensweise hier ist besser.
Meine Anwendung hat nun abgesehen von den Login- und MainFrame-Formularen vier verschiedene Dialoge zum Neuanlegen und Ändern von Daten. Dialoge unterscheiden sich von Formularen dadurch dass sie modal aufgerufen werden, sie also erst geschlossen werden müssen bevor andere Fenster des Programms bedient werden können. Diese vier Dialoge sind:
- Ein Dialog zum Neuanlegen und Ändern von Projekten
- Ein Dialog zum Neuanlegen und Ändern von Ansprechpartnern
- Ein Dialog zum Neuanlegen und Ändern von Unternehmen
- Ein Dialog zum Neuanlegen und Ändern von Studenten
Ein Anfänger hätte nun acht verschiedene Methoden geschrieben, weil es vier Dialoge sind und sie jeweils im Ändern- oder Neuanlegen-Modus aufgerufen werden müssen. Das ist aber unklug und es gibt Tricks um dies zu einer Methode zusammenzufassen, siehe meine OpenDialog-Methode im MainFrame:
/**
* Öffnet einen Dialog im Neuanlegen- oder Ändern-Modus
*
* @param viewClass
* Klasse des zu öffnenden Dialogs
* @param caption
* Fensterbeschriftung
* @param newMode
* Newmodus ja/nein
* @param activeTable
* aktive JTable für Listendarstellung
* @param activeData
* aktive Liste von Objekten, die der aktiven JTable
* zugrundeliegt
* @param roleTyp * Benutzertyp mit dem eingeloggt wurde
*/
private void openDialog(final Class viewClass, final String caption,
final boolean newMode, final JTable activeTable,
final List<Object> activeData, final UserRole roleType) {
SwingUtilities.invokeLater(new Runnable() {
public void run() {
boolean OK = true;
Object changeObject = null;
if (!newMode) {
if (activeTable.getSelectedRow() < 0) {
OK = false;
} else {
changeObject = activeData.get(activeTable
.getSelectedRow());
}
}
if (!OK) {
JOptionPane
.showMessageDialog(
null,
"Bitte wählen Sie einen Datensatz in der Tabelle aus.",
"Fehler", JOptionPane.ERROR_MESSAGE);
} else {
/**
* View aus Dialog-Liste des Controllers holen, soll nicht
* immer neu instanziiert werden
*/
AbstractDialog view = controller.getDialog(viewClass);
/**
* noch nicht in View-Liste des Controllers, instanziieren
* und hinzufügen
*/
if (view == null) { /**
* da alle Dialoge denselben Konstruktor haben kann
* folgender Trick angewandt werden, durch den ein
* expliziter Cast pro Dialog-Klasse vermieden werden
* kann.
*
* Entnommen aus:
* http://www.coderanch.com/t/405877/java/
* java/Dynamic-Casting
*/
try {
Constructor<?> cons = (Constructor<?>) viewClass
.getConstructor(new Class<?>[] {
JFrame.class, Controller.class,
String.class, UserRole.class });
try {
view = (AbstractDialog) cons
.newInstance(new Object[] { mainFrame,
controller, caption, roleType });
} catch (InstantiationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InvocationTargetException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} catch (NoSuchMethodException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SecurityException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
/**
* als Beobachter hinzufügen
*/
controller.addObserver(view);
/**
* der Dialog-Liste im Controller hinzufügen
*/
controller.addDialog(view);
}
view.pack();
// positionieren des Fensters: mittig
view.setLocationRelativeTo(null);
view.setModalityType(ModalityType.DOCUMENT_MODAL);
/**
* Daten zurücksetzen und anzeigen
*/
view.initialize(caption, changeObject);
view.setVisible(true);
}
}
});
}
Man beachte hierbei folgende Tricks:
1. Die bereits zuvor beschriebene Methode um ein Formular- respektive Dialog-Objekt anhand des Klassentyps aus der ArrayListe des Controllers zu holen oder neu zu instanziieren.
2. Alle vier Dialoge haben grundsätzlich denselben Konstruktor, es werden folgende Parameter benötigt:
construktor(JFrame owner, final Controller controller, String label, final UserRole roleType)
Um an der Stelle Casts und damit Fallunterscheidungen zu vermeiden wird der Konstruktor dynamisch über die getConstructor-Methode geholt und dann mittels der Constructor<?>.newInstance(Variable1, Variable2, Variable3, Variable4)-Methode instanziiert.
Auf diese Weise muss diese Methode nie erweitert werden, egal wieviele Dialoge man noch hinzufügt. Die Bedingung dafür ist aber dass alle hinzukommenden Dialoge dieselbe Parameterliste im Konstruktor haben und ebenfalls von AbstractDialog ableiten.
3. Bei mir behandeln alle Dialoge immer den Neuanlegen- und Ändern-Modus. Dadurch ist es aber immer noch dasselbe Objekt in der ArrayList des Controllers.
Deswegen habe ich bei mir eine Initialize-Methode in allen Dialogen eingeführt, die folgende Signatur besitzt:
public void initialize(final String label, final Object changeObject)
Der Konstruktor wird ja nicht mehr immer aufgerufen, daher ist es notwendig im Neuanlegen-Modus immer alle Eingabefelder zurückzusetzen. Im Ändern-Modus werden die Eingabefelder dagegen auf die Werte des changeObjekts gesetzt. Dies alles geschieht in der Initialize-Methode.
Damit nun keine Fallunterscheidungen – Casts je nach Dialog – in der OpenDialog-Methode gemacht werden müssen wurde diese Methoden-Signatur in die abstrakte Basisklasse der Dialoge “nach oben” verlagert. In den abgeleiteten Klassen wird diese Methode dann überschrieben und damit tatsächlich implementiert.
Durch diese Tricks muss die OpenDialog-Methode tatsächlich nie erweitert werden.
Eine der Ziele moderner Programmierung muss es sein die Anzahl der Casts zu reduzieren und somit händisches Nacharbeiten nach einer Programmerweiterung zu reduzieren. Mit diesen Ausführungen habe ich Ansätze gezeigt wodurch dies ermöglicht wird.
In der Hinsicht sollte übrigens auch Reflection beachtet werden.
Die abstrakte Basisklasse der Dialoge
So weit es ging habe ich den Code, der von allen Dialogen benötigt wird, in die abstrakte Basisklasse der Dialoge verlagert um Quellcode-Wiederholungen zu vermeiden.
Zum Beispiel hat jeder Dialog einen Übernehmen- und Abbrechen-Button. Jeder Dialog ruft im Konstruktor zunächst den Basisklassen-Konstruktor auf. Im Konstruktor der Basisklasse werden diese zwei Buttons instanziiert – und das zugehörige Buttonpanel - und über den protected-Zugriffsmodifizierer den abgeleiteten Klassen verfügbar gemacht.
In den abgeleiteten Klassen wird das Buttonpanel dann dem Dialog hinzugefügt, wobei jeder abgeleitete Dialog die saveData-Methode der Basisklasse überschreiben und implementieren muss.
Weitere Funktionen der abstrakten Basisklasse der Dialoge sind:
- initializeFieldsWithColors: Die Basisklasse beherbergt eine Komponentenliste der erforderlichen Pflichtfelder, die von den abgeleiteten Klassen gefüllt wird. In dieser Methode werden diese Felder mit den Default-Farben der Pflichtfelder gefüllt.
- getColumnLength: Auslesen der erlaubten Maximallänge eines Textfeldes aus den Annotationen der Entities.
- preSelection: Vorselektion, wird aus dem Konstruktor heraus aufgerufen.
- Eine Default-Implementierung der update-Methode für das Observer-Pattern.
- checkValidEmail: Überprüfen ob die angegebene JTextField-Komponente eine gültige E-Mail-Adresse enthält. Benutzt ein RegEx-Pattern.
- checkValidOnlyNumbers: Überprüfen ob die angegebene JTextField-Komponente wirklich nur Zahlen enthält. Benutzt ein RegEx-Pattern.
- updateGUIData: Füllt die Comboboxen erneut wenn über das Observer-Pattern für den Dialog relevante Daten zurückgeliefert wurden. Wichtig hierbei ist dass sich zuerst gemerkt wird welche Auswahl der Benutzer davor getroffen hatte. Nach dem Leeren und Füllen der Combobox wird die alte Selektion erneut gesetzt so dass der Benutzer keinen Änderung bemerkt. Ganz wichtig dabei war auch zunächst die ItemListener der Comboboxen zu deaktivieren damit das ItemChanged-Event nicht bei jedem Hinzufügen eines Eintrages gefeuert wird. Am Schluss wird der ItemListener natürlich wieder aktiviert. Zu diesem Zweck war es übrigens notwendig einen eigenen ItemListener zu implementieren um dies zu ermöglichen.
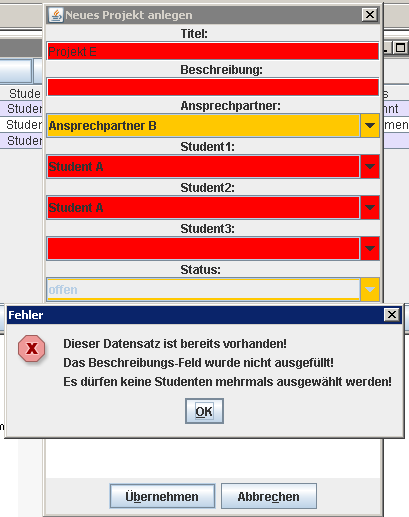
- checkExistingRecord: Speziell bei Projekten und Unternehmen soll zunächst überprüft werden ob sie mit diesem Namen bereits existieren und eine Neuanlage unter gleichem Namen verhindert werden. Im Ändern-Modus wird das eigene Objekt nicht berücksichtigt.
- closeFormOnDeleteCascading: Eine Methode die das kaskadierende Löschen von Detaildatensätzen der Datenbank abfängt. Wenn z. B. Datensatz A einen Datensatz B referenziert, der Benutzer will gerade Datensatz A ändern und ein anderer Benutzer löscht gleichzeitig an einem anderen Rechner gerade Datensatz B oder sogar Datensatz A, dann wird das davon betroffene Fenster des ersten Benutzers automatisch mit einer Fehlermeldung geschlossen weil der Datensatz ja nicht mehr vorhanden ist.
Die drei letztgenannten Methoden benutzen Reflection, um händisches Nacharbeiten soweit wie möglich zu verringern. Die getId-Methode beispielsweise ist ja in allen Entity-Klassen vorhanden.
Auf diese Weise ist das Programm tatsächlich durchgängig Multi-User-fähig, bloß eines habe ich noch unberücksichtigt gelassen: Wenn zwei Anwender gleichzeitig denselben Datensatz ändern wollen, wer gewinnt dann? Zu diesem Zweck muss ich mich noch intensiver mit Optimistic vs. Pessimistic-Locking auseinander setzen. Das Programm geht aber auch so schon über das im Studium Gelehrte hinaus.
Wichtig war mir dann noch dass bei Fehlermeldungen diese gesammelt einmalig untereinander ausgegeben werden, nicht also mehrfach eine Fehlermeldung hintereinander angezeigt wird. Dazu befindet sich in der Basisklasse eine ArrayListe für die Fehlermeldungen, diese wird von den Dialogen entsprechend gefüllt und dann die Methode der Basisklasse aufgerufen die diese kumulierte Fehlermeldung anzeigt und die Liste wieder leert.
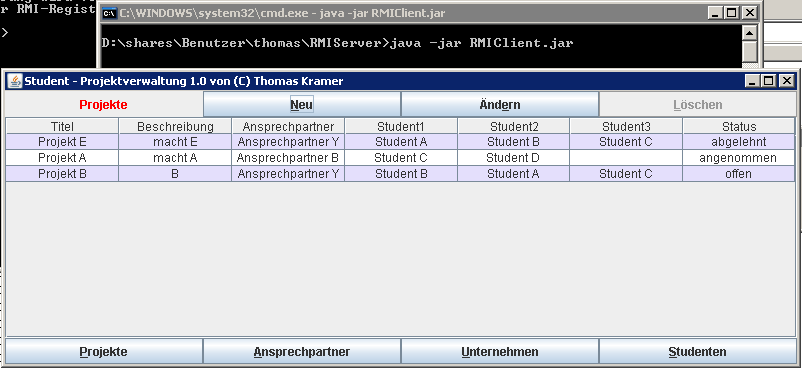
Nachfolgend noch Bilder des Clients:
Update 14.02.2013: Um noch einmal auf die oben ausgeführte Situation zurückzukommen, wonach ein Benutzer X gerade Datensatz A bearbeitet welcher Datensatz B referenziert und ein anderer Benutzer Y will gerade Datensatz B löschen.
Wie reagiert man auf die Aktion von Benutzer Y? Mir fallen da zwei Möglichkeiten ein – wenn die Foreign-Key-Spalte in Datensatz A datenbankseitig ein Pflichtfeld ist:
1. Das Löschen von Datensatz B wird dem Benutzer Y untersagt weil Benutzer X gerade Datensatz A bearbeitet welcher Datensatz B referenziert.
2. Das Löschen von Datensatz B wird dem Benutzer Y erlaubt und das Fenster des Benutzers X automatisch mit einer Fehlermeldung geschlossen weil sein gerade bearbeiteter Datensatz A Datensatz B referenziert und durch das kaskadierende Löschen automatisch mitgelöscht wurde.
Zur Zeit implementiert mein Client nur die zweite Möglichkeit. Die zweite Methode scheint auf den ersten Blick schlechter als die Erste zu sein, jedoch denke ich dass es bei umfangreicheren Anwendungen Benutzer mit verschiedenen Rechten geben muss – normale Benutzer und Administratoren.
Daher denke ich dass eine fortgeschrittene Multi-User-Anwendung beide Möglichkeiten implementieren muss.
Update 15.02.2013: Aus Delphi kenne ich noch das Problem beim Hinzufügen vieler Datensätze zu einem DataGrid, dass dies sehr langsam vonstatten ging bis man das Neuzeichnen während des Hinzufügens der Zeilen deaktivierte. Das ist absolut nachvollziehbar, nur fällt so etwas beim Entwickeln häufig erst nach Last-Tests auf. Ich schreibe mir das hier auf damit ich das beim nächsten Mal direkt berücksichtige.
Update 18.02.2013: Die getDialog/addDialog-Methoden im Client-Controller können noch zusammengefasst werden indem die Konstruktor-Parameter als Class- und Objekt-Array übergeben werden.
Update 11.06.2013: Weiter oben schrieb ich dass wegen RMI client-seitig die Firewalls komplett deaktiviert werden müssen damit die Kommunikation funktioniert. Das stimmt insofern dass RMI client-seitig zufällige Ports verwendet, aber bei der Windows-Firewall können nicht nur bestimmte Ports geöffnet sondern auch gezielt Programme durchgelassen werden.
Es müsste demnach eigentlich ausreichen den Datenverkehr für die javaw.exe vollständig freizugeben in den Client-Firewalls. Das ist immer noch besser als die Firewall komplett zu deaktivieren.
Die Sourcecodes
Die Sourcecodes stehen grob gesagt unter folgender Lizenz: Die Benutzung in privaten oder Freeware-Projekten ist erlaubt sofern mein Name und meine E-Mail-Adresse (th-rzv [at] gmx.de) im About-Dialog oder der beigefügten Dokumentation erscheinen.
Die kommerzielle Nutzung erfordert dagegen meine schriftliche Genehmigung – dabei handelt es sich um eine übliche Lizenz.
Nachfolgend meine Quellcodes und die mittels doxygen generierte HTML-Dokumentation. Die Datei index.html stellt übrigens den jeweiligen Startpunkt der Dokumentation dar. Wenn GraphViz zuvor installiert wurde kann doxygen übrigens richtig gute Abhängigkeitsdiagramme automatisch erstellen, für ein kostenloses Programm ist das gar nicht schlecht.
RmiClient.zip
client.policy
RmiClient-Dokumentation
RmiServer.zip
server.policy
RmiServer-Dokumentation
Außerdem wurden die erforderlichen Bibliotheken aus den Paketen entfernt, die Abhängigkeiten sehen wie folgt aus – die entsprechenden Dateien müssen in den jeweiligen Libs-Ordner kopiert werden:
Client-seitig:
EclipseLink-Datenbankzugriffsschicht – elipselink.jar und javax.persistence_2.0.4.v201112161009.jar
Server-seitig:
EclipseLink-Datenbankzugriffsschicht – elipselink.jar und javax.persistence_2.0.4.v201112161009.jar
HSQLDB-Datenbank – hsqldb.jar, das Paket enthält auch den JDBC-Treiber
JAMon-Performancemonitor – jamon-2.74.jar
Log4j-Logging-Framework – log4j-1.2.17.jar
Die erforderlichen HSQLDB-Datenbankdateien des Servers, diese müssen im gleichen Pfad wie der Anwendungsserver liegen:
hsql_db.properties
hsql_db.script
Soweit meine erste RMI-Anwendung, beim nächsten Mal würde ich aber statt RMI eher einen Java Message Service wie Apache ActiveMQ benutzen.
Links
Generell ist stackoverflow.com immer eine gute Anlaufstelle zu programmiertechnischen Problemen.
Links speziell zu RMI:
Das Buch “Kommunikation in verteilten Anwendungen” bei Google Books: Link
Ein Artikel zu Java-RMI bei Oracle: Link
Ein Beispiel für die Implementierung eines Remote-Observers über RMI: Link
Der Abschnitt “Verteilte Programmierung mit RMI” aus dem Online-Buch “Java ist auch eine Insel”: Link
Das “RMI Mini Tutorial” von der TU Darmstadt: Link
Die konkurrierende Technik SIMON erläutert auf der Webseite warum ich auch eine CustomSocketFactory für RMI benutzen musste: Link
Der SecurityManager im Buch “Java ist auch eine Insel”: Link
Der Artikel “Getting Java RMI Working”: Link
Der Artikel “Effizientes RMI für Java” der Universität Karlsruhe: Link
Der Artikel “RMI Performance Tips”: Link
Der Artikel “Using a Custom RMI Socket Factory” bei Oracle: Link
Ein weiterer Oracle-Artikel zu “Using Custom Socket Factories with Java RMI”: Link
Setzen von Timeouts bei einer eigenen Socket Factory: Link
Ein Tutorial zur Verwendung des Security Managers mit RMI: Link
Links speziell zu EclipseLink/JPA:
Der Artikel “Java Persistence Entity Operations”: Link
Eine Übersicht der EntityManager-API-Funktionen: Link
Ein sehr guter technischer Artikel zu JPA von torsten-horn.de: Link
Der Artikel “Locking in JPA” von ObjectDB: Link
Der Artikel “Pessimistic and Optimistic Locking in JPA 2.0”: Link
Dieser Artikel rät dazu Version-Annotationen bei den Entity-Klassen einzuführen um Inkonsistenzen zu vermeiden: Link
Optimistic Locking bei EclipseLink unter Verwendung der @Version-Annotation: Link
EclipseLink verwendet einen gemeinsamen Cache, dieser kann händisch deaktiviert oder refresht werden wenn nötig: Link
Allgemeine Links:
LinkedList vs. ArrayList im Geschwindigkeitsvergleich: Link